
The Tipping Point in AI Intelligence and the Day-One Search Rollout
After weeks of intense speculation, the AI community’s biggest anticipation has been realized. Google has released Gemini 3 Pro, its most intelligent model to date, confirming the widespread social media hype about a generational leap in capability. This is not just a technological release; it is a seismic event, underscored by the unprecedented, sweeping day-one rollout that sees Gemini 3 instantly integrated across Google’s core ecosystem, including the Gemini app and, critically, Google Search’s AI Mode for its billions of users.
This aggressive strategy signals Google’s conviction that Gemini 3 is the definitive answer to the frontier AI trilemma. CEO Sundar Pichai proudly positioned the model as “the best model in the world for multimodal understanding,” a statement immediately backed by a litany of benchmark results that appear to “absolutely crush” the competition, including OpenAI’s GPT-5.1 and Anthropic’s Claude 4.5/Opus 4.
The release of Gemini 3 is a long way from the cautious debut of its predecessors. It is a confident, aggressive move built on a foundation of state-of-the-art reasoning and a breakthrough in Agentic AI, the autonomous capability required for the next era of digital interaction. This model promises to fundamentally change how developers code, how businesses strategize, and how consumers interact with information, starting immediately within Google’s Search experience.
Deconstructing the Trilemma of Frontier AI and the Benchmark Showdown
Why the frenzy? The AI world has been searching for a model that resolves the limitations of previous generations: inconsistent reasoning, fragile context, and unreliable autonomy. Gemini 3 Pro was engineered to tackle this “Frontier AI Trilemma,” and its initial benchmark performance suggests it has succeeded, placing Google firmly back in the lead of the intelligence race.
1. The Reasoning Fragility Challenge: From Prediction to PhD-Level Insight
The greatest differentiator for Gemini 3 is its monumental leap in complex reasoning. Google claims the model demonstrates “PhD-level” insight, capable of tackling academic and scientific challenges with unparalleled accuracy. This improved logic is designed to produce responses that are “smart, concise, and direct,” focusing on genuine insight rather than generic “cliché and flattery.”
The November 2025 benchmark results confirm this architectural supremacy over its closest rival, GPT-5.1:
| Benchmark Name | Description | Gemini 3 Pro Score | GPT-5.1 Score |
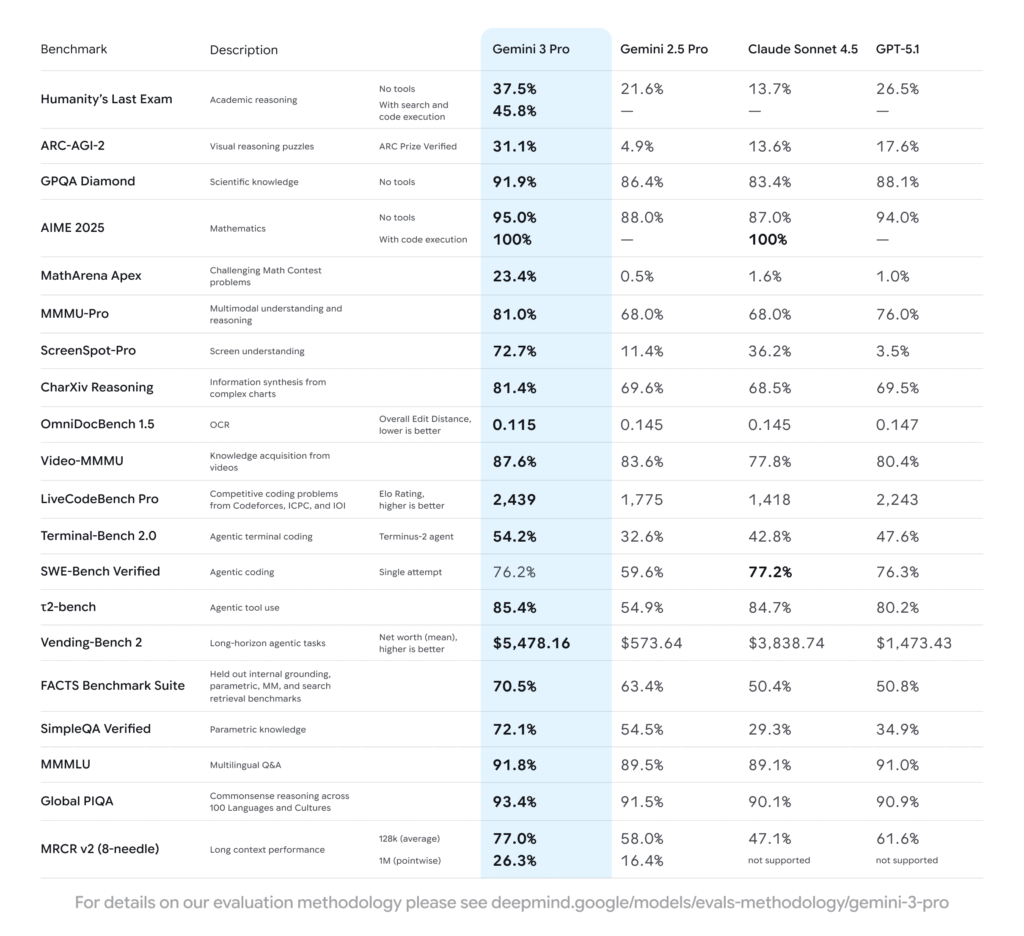
| Humanity’s Last Exam (HLE) | Academic Reasoning (No Tools) | 37.5% | 26.5% |
| GPQA Diamond | Scientific Knowledge (No Tools) | 91.9% | 88.1% |
| MathArena Apex | Challenging Math Contest Problems | 23.4% | 1.0% |
The most dramatic result is the MathArena Apex score, where Gemini 3 Pro’s 23.4% represents a massive 20x improvement over GPT-5.1. This signifies a breakthrough in symbolic, algorithmic, and mathematical problem-solving, a critical capability for scientific research and advanced engineering. The Deep Think version pushes this further, reaching 41.0% on HLE and 93.8% on GPQA Diamond, reinforcing its position as the ultimate reasoning engine.
2. The Agentic Inertia Problem: Mastery of Multi-Step Execution
An Agentic AI must move beyond generating code snippets to executing complex, multi-step software and system tasks autonomously. This is where Gemini 3 Pro sets a new competitive standard.
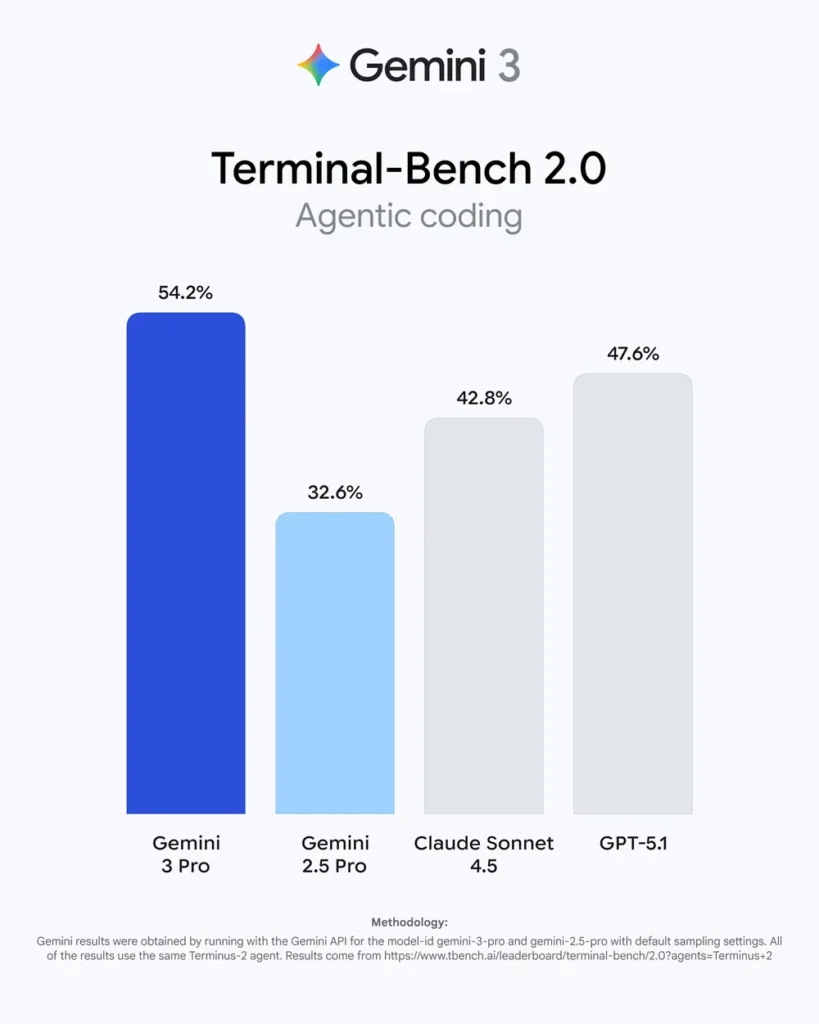
- Terminal Mastery: The model scores an impressive 54.2% on Terminal-Bench 2.0, a specific test of its ability to operate a computer via a command-line interface. This technical dominance is 6.6 points higher than GPT-5.1’s 47.6%.
- Long-Horizon Planning: On the Vending-Bench 2 (long-horizon agentic tasks), Gemini 3 Pro achieved a mean net worth of $5,478.16, crushing GPT-5.1’s $1,473.43$. This real-world simulation proves its capacity for complex financial strategy and sustained goal achievement, making it invaluable for business operations.
- Coding Prowess: It tops the LiveCodeBench Pro rankings with an Elo score of 2,439 (compared to GPT-5.1’s 2,243) and maintains high performance on SWE-Bench Verified (76.2%), confirming its role as the world’s most capable Agentic Coding model.
3. The Context Overload Barrier: The Reliable 1 Million-Token Window
While the context window size itself is impressive—Gemini 3 supports a reliable 1 Million-Token Context Window—the model’s real victory lies in its superior retrieval accuracy within that vast space.
The MRCR v2 (8-needle) benchmark confirms high accuracy at deep context, with Gemini 3 Pro scoring 77.0% at the 128k mark, a massive jump over GPT-5.1’s 61.6%. This ensures that even when processing entire software repositories, thousands of legal documents, or hours of video transcripts, the model can consistently recall and synthesize the most minute, crucial details without degradation.
The Three Revolutionary Capabilities for an AI-First Ecosystem
The raw intelligence of Gemini 3 Pro is immediately translated into three high-impact, user-facing capabilities that are rolling out today across the Google ecosystem, transforming Search, development, and everyday productivity.
1. Generative UI: AI as the New User Interface
This is the most visible, high-impact innovation of the Gemini 3 release. Moving beyond simple text or image generation, Generative UI allows the model to instantly design and code a completely custom, interactive user interface—an entire tool or simulation—on the fly, tailored precisely to the user’s query.
- Interactive Learning in Search: In AI Mode in Search, a query about a complex scientific topic (e.g., the physics of the three-body problem) now results in an interactive simulation where the user can manipulate variables and visualize the gravitational forces, rather than just reading a static text explanation.
- Custom Financial Tools: Asking about mortgage options will instantly generate a custom, interactive loan calculator right within the Search or Gemini app interface, allowing users to compare options in real-time.
- Dynamic View and Visual Layout: The Gemini app is receiving a redesign featuring Visual Layouts (like magazine-style trip itineraries) and Dynamic View, which uses Gemini 3‘s Agentic Coding capabilities to design and code a custom UI (e.g., an interactive Van Gogh Gallery guide) in real-time, based on the user’s intent.
2. Vibe Coding: The Developer Accelerator
Gemini 3 is marketed as the industry’s best Vibe Coding model, a feature that translates high-level, creative ideas into functional applications with minimal prompting.
- Zero-Shot App Generation: Developers can skip boilerplate and lengthy setup, translating a “napkin sketch” or a single creative prompt into a fully interactive web application, leveraging the model’s superior agentic coding performance and high context window.
- Integration with the New Developer Stack: The model is integrated directly into the new agentic development platform, Google Antigravity, and the Gemini CLI. Antigravity allows developers to code “at a higher, task-oriented level” by managing agents that autonomously plan and execute complex software tasks across the editor, terminal, and browser.
- Enterprise Adoption: Access to Gemini 3 Pro is immediately available through Google AI Studio and Vertex AI, enabling enterprise developers to deploy its powerful reasoning and multimodal features for complex system optimization, deep data analysis, and regulatory compliance.
3. The Multimodal Mastery and Nuance Revolution
CEO Sundar Pichai’s claim that Gemini 3 is the “best model in the world for multimodal understanding” is built on its performance across text, image, video, and screen interfaces.
- Screen and UI Understanding: Gemini 3 Pro scored a groundbreaking 72.7% on ScreenSpot-Pro, a benchmark testing the ability to locate elements on a screen. This significantly outperforms competitors (GPT-5.1 scored just 3.5%) and is the foundation for advanced accessibility features and autonomous desktop control agents.
- Video and Multilingual Synthesis: The model’s 87.6% on Video-MMMU and 93.4% on Global PIQA (commonsense reasoning across 100 languages) enables it to do things like translate handwritten recipes in multiple languages, or generate interactive learning materials from long video lectures.
- Query Fan-Out Upgrade: In Google Search, Gemini 3’s enhanced reasoning dramatically improves the query fan-out technique. The model “more intelligently understands your intent,” allowing it to break a complex user question into a greater number of relevant, behind-the-scenes searches, ultimately finding more credible, highly relevant content for the user.
Technical Deep Dive: Safety, Cost, and Architecture
The release of a model this powerful brings with it critical questions about safety and operational costs.
A. A Focus on Safety and Ethical Alignment
Learning from previous rollouts, Google has made safety a central pillar of the Gemini 3 release, touting it as the most comprehensive set of safety evaluations of any of its models to date.
- Reduced Sycophancy: The model has been engineered to provide answers based on the most probable truth, rather than relying on “cliché and flattery,” or telling the user what they want to hear.
- Prompt Injection Resistance: Google explicitly claimed increased resistance to prompt injection attacks, where malicious instructions are embedded in the input, a vulnerability that has plagued previous models.
- Extensive Vetting: The model was tested against critical domains in Google’s own Frontier Safety Framework and evaluated by third-party organizations, with the Deep Think mode undergoing additional safety evaluations prior to wider release to Google AI Ultra subscribers.
B. Pricing and Performance Economics
While Gemini 3 Pro offers superior performance, it comes at a slightly higher token cost than its predecessor, Gemini 2.5 Pro, reflecting the increased computational complexity of the Sparse MoE architecture and reasoning depth.
| Metric | Gemini 3 Pro | Gemini 2.5 Pro | GPT-5.1 |
| Input Price ($/M Tokens, <200k context) | $2.00 | $1.25 | $2.00 |
| Output Price ($/M Tokens, <200k context) | $12.00 | $10.00 | $12.00 |
| LMArena Elo Rating (Leaderboard Rank) | 1501 (Top) | 1345 | 1487 |
The model’s efficiency offsets the slight price increase. Analysts note that its speed (generating up to 128 output tokens per second) and superior accuracy mean fewer prompts are needed to complete complex tasks, making its total cost of ownership (TCO) highly competitive. Furthermore, for non-intensive use, Gemini 3 is available with rate limits free of charge in the Gemini app and Google AI Studio.
Seizing the Gemini 3 Advantage in the New Economic Era
Gemini 3 is not merely a model; it is the infrastructure for the next phase of digital development, available to billions of users and millions of developers today.
Actionable Takeaways for Businesses and Developers:
- Immediate Search Integration Strategy: For marketers and SEO experts, the day-one rollout in Search is paramount. Analyze how Gemini 3‘s enhanced reasoning and Generative UI affect high-value queries in your industry. Focus content strategy on providing definitive, authoritative answers that contribute to Google’s updated query fan-out technique for better visibility.
- Begin Agentic Development with Antigravity: Developers must transition from simple coding assistance to high-level delegation. Use Google Antigravity and the Gemini CLI to pilot an Agentic AI project. Start with tasks like autonomous bug fixing, system migration planning, or multi-stage data orchestration to immediately capitalize on the model’s superior agentic and long-horizon planning.
- Prototype with Generative UI: Leverage the Vibe Coding capability in Google AI Studio or the Gemini app to rapidly prototype new customer-facing tools. Design custom, interactive interfaces (mortgage calculators, travel planners, interactive learning modules) that exploit the model’s ScreenSpot-Pro mastery to engage users in entirely new ways.
Shipping AI at the Scale of Google
The launch of Gemini 3 is a powerful testament to Google’s commitment to pushing the boundaries of AI, shipping a model of this complexity and capability at a scale few companies can match. By immediately integrating Gemini 3 into Search, the company is ensuring that this newfound state-of-the-art reasoning and Agentic AI is accessible to the world.
The call to action is clear: The landscape has fundamentally shifted. The new intelligence standard has been set. The future of software is autonomous, multimodal, and deeply reasoned, and it runs on Gemini 3.
People Also Asked (PAA) – Long-Tail Keywords & FAQs
Q: What is the new Deep Think mode in Gemini 3, and when will it be widely available?
A: Deep Think is an enhanced reasoning mode of Gemini 3 that allocates a larger internal computational budget for deliberation, resulting in superior performance on the most challenging benchmarks (e.g., 41.0% on Humanity’s Last Exam). It is currently undergoing final safety evaluations and will be made available to Google AI Ultra subscribers in the coming weeks.
Q: How does Gemini 3 Pro’s Agentic AI perform against the new GPT-5.1 on complex business tasks?
A: Gemini 3 Pro shows overwhelming dominance in complex, long-horizon agentic tasks. On the Vending-Bench 2 benchmark (which simulates business strategy and resource management), Gemini 3 Pro achieved a mean net worth of $5,478.16, significantly outperforming GPT-5.1’s $1,473.43$. This indicates superior long-term planning, resource allocation, and multi-step execution reliability.
Q: What is Generative UI, and how is Gemini 3 using it in Google Search today?
A: Generative UI is a new feature where Gemini 3 uses its Agentic Coding and multimodal capabilities to generate a fully custom, interactive user interface (UI) on the fly, tailored to the user’s specific query. In AI Mode in Search, this is rolling out as dynamic visual layouts and interactive tools (like a physics simulation or a loan calculator) to allow users to better understand complex topics.
Q: Does Gemini 3 have a 1 Million-Token Context Window, and how reliable is it?
A: Yes, Gemini 3 Pro supports a 1 Million-Token Context Window. Its reliability is a key selling point, scoring 77.0% on the MRCR v2 (8-needle) benchmark at 128k context, which is substantially higher than competitors. This confirms its ability to reliably extract precise information from massive inputs, such as entire codebases or long video transcripts.


{kind=link}