
Gemini 3 Flash: The New Speed King of AI (Review & Guide)
Is it possible to have PhD-level intelligence without the “thinking” latency?
For years, developers and enterprises have faced a brutal trade-off: choose the raw intelligence of a “Pro” model and suffer slower load metrics, or choose a “Flash” model for speed and sacrifice reasoning capabilities.
That trade-off ends today.
With the release of Gemini 3 Flash, Google has effectively reset the board. Rolling out globally as of December 2025, this model isn’t just an incremental update it is a paradigm shift. It delivers the complex reasoning of Gemini 3 Pro with the lightning-fast latency of the Flash series, all while slashing costs by nearly 70% compared to previous generations.
In this guide, we dive deep into the Gemini 3 Flash architecture, its groundbreaking benchmarks, and why it is rapidly becoming the default engine for the next generation of AI agents.
1. The Evolution of Speed: What is Gemini 3 Flash?
Gemini 3 Flash is Google’s latest “frontier intelligence” model built specifically for high-frequency, low-latency tasks.2 While the flagship Gemini 3 Pro and Gemini 3 Deep Think focus on exhaustive reasoning for scientific discovery, Flash is designed to be the workhorse of the AI economy.
But don’t let the “Flash” moniker fool you. This isn’t a “lite” version of a smarter model.
Key Innovations
- Pareto Frontier efficiency: It processes load metrics and tokens 3x faster than Gemini 2.5 Pro.
- Intelligent Modulation: Unlike previous iterations, Gemini 3 Flash can dynamically modulate its “thinking” depth. It knows when to answer instantly and when to pause for complex reasoning, using 30% fewer tokens on average to get to the right answer.
- Multimodal Native: It can “see” and “hear” with near real-time latency, making it capable of analyzing video streams or vetting UI designs instantly.
Expert Insight: “Gemini 3 Flash demonstrates that speed and scale don’t have to come at the cost of intelligence. It delivers frontier performance on PhD-level reasoning benchmarks like GPQA Diamond, rivaling larger frontier models.” – Tulsee Doshi, Senior Director, Product Management at Google.
2. Gemini 3 Flash Benchmarks: Pro Performance at Flash Speeds
When comparing Gemini 3 Pro vs Flash, the gap has narrowed significantly. In fact, for many real-world applications, Gemini 3 Flash is now the superior choice due to its responsiveness.
The Breakdown
We analyzed the Gemini 3 Flash benchmarks against its predecessor (Gemini 2.5 Pro) and the current heavyweight, Gemini 3 Pro.10
| Benchmark | Metric | Gemini 3 Flash Score | vs. Gemini 2.5 Pro |
| GPQA Diamond | PhD-Level Science | 90.4% | Significant Increase |
| MMMU Pro | Multimodal Reasoning | 81.2% | +13.2% |
| SWE-bench Verified | Coding Agents | 78.0% | Outperforms 2.5 Pro |
| Humanity’s Last Exam | Hardest Reasoning | 33.7% | Comparable to Frontier Models |
Analysis:
The standout stat here is the 78% on SWE-bench Verified. This score means Gemini 3 Flash is not just a chatbot; it is a highly capable coding agent.11 It outperforms the entire Gemini 2.5 series and even beats Gemini 3 Pro in specific high-velocity coding tasks where iterative speed trumps deep contemplation.
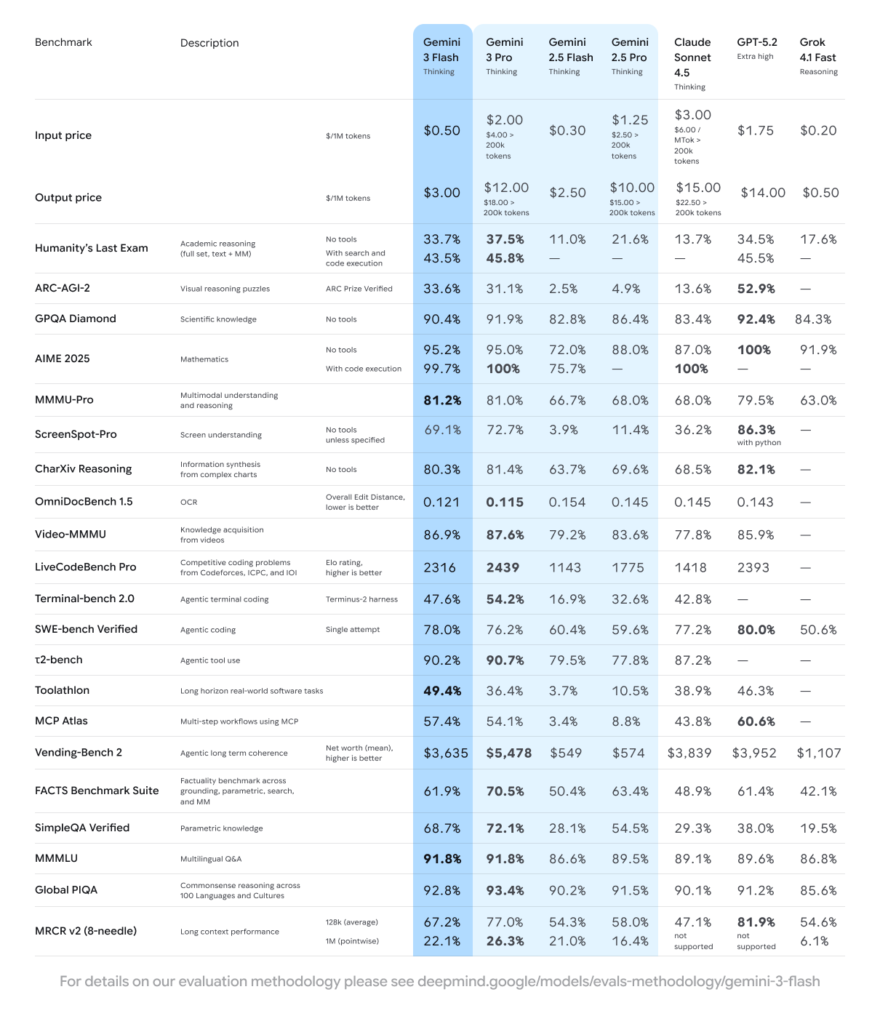
In the Gemini 3 Flash preview tests, the model scored 86.9% on Video-MMMU, meaning it can watch a YouTube video or analyze a live stream and understand the context better than most humans can in real-time.
3. Developer & Enterprise Use Cases: Why Upgrade?
The shift to Gemini models like Flash is being driven by two factors: Agentic workflows and Cost.
The Engine for Google Antigravity
The launch of Gemini 3 Flash coincides with the rise of Google Antigravity, Google’s new agentic development platform.14 In this environment, AI agents don’t just write code; they plan, execute, and debug entire applications autonomously.15
- Vibe Coding: Developers are using Flash to “vibe code” iterating on UI/UX designs in real-time. You can sketch a layout, show it to the model, and have a working interactive prototype in seconds.
- A/B Testing Agents: Companies like Figma and Bridgewater Associates are using Gemini 3 Flash to run thousands of simultaneous A/B tests, where the AI analyzes user behavior and adjusts the code on the fly.
Enterprise Scale
For enterprises using Vertex AI, the ability to process massive datasets (like long-form video archives or years of financial records) at “Flash” speeds changes the ROI calculation.
Case Study: A major gaming studio used Gemini 3 Flash to power in-game NPCs. The latency was so low that characters could “see” player actions and react verbally with zero perceptible delay, a feat impossible with the heavier Gemini 3 Pro.
4. Gemini 3 Flash Pricing & Technical Specs
One of the most aggressive moves Google has made is in the Gemini 3 Flash pricing strategy. They have effectively commoditized high-level intelligence.
The Pricing Model (Gemini API)
Pricing is structured to encourage high-volume usage via AI Studio and the API.
- Input Cost: $0.50 / 1 million tokens16
- Output Cost: $3.00 / 1 million tokens17
- Audio Input: $1.00 / 1 million tokens
Gemini 3 API users also benefit from the “context caching” features, which further reduce costs for repetitive tasks like querying large documents.
How to Access
- Developers: Access the model immediately via Google AI Studio or the Gemini API.18
- General Users: Gemini 3 Flash is now the default model in the free version of the Gemini App and “AI Mode” in Google Search.19
- Enterprise: Available via Vertex AI and Gemini Enterprise plans.20
Load Metrics & Latency
For developers monitoring load metrics, Gemini 3 Flash offers a “Time to First Token” (TTFT) that is consistently sub-500ms, even for complex queries. This low latency is critical for voice apps and real-time agents.21
Gemini 3 Flash: Frontier intelligence, built for speed
People Also Asked (FAQ)
Q: What is the difference between Gemini 3 Pro vs Flash?
A: Gemini 3 Pro is designed for complex, multi-step reasoning and deep research (using “Deep Think” mode).22 Gemini 3 Flash is optimized for speed, efficiency, and high-frequency tasks, making it 3x faster and significantly cheaper, though slightly less capable on extremely nuanced physics or math problems.23
Q: Is Gemini 3 Flash free?
A: Yes, for general users, Gemini 3 Flash is the default model in the free Gemini app.24 Developers using the Gemini API pay per token (approx. $0.50/1M input).25
Q: Can Gemini 3 Flash write code?
A: Absolutely. It scores 78% on the SWE-bench Verified benchmark, making it one of the most capable coding models available, especially for iterative “vibe coding” workflows.26
Q: What is the Gemini 3 Flash context window?
A: Like its predecessors, it supports a massive context window (up to 1M+ tokens in preview), allowing it to ingest entire books, codebases, or long videos in a single prompt.
Q: How does Gemini 3 Flash benchmarks compare to GPT-5?
A: While direct comparisons vary, Gemini 3 Flash often matches or exceeds “Pro” level models from early 2025 in reasoning, while winning decisively on price-performance and speed metrics.
Conclusion: The “Default” Model for 2026
The release of Gemini 3 Flash marks a turning point. We are no longer waiting for AI to be “smart enough”; we are now optimizing for how fast and affordable that intelligence can be deployed.
For developers, the Gemini 3 API offers an unbeatable combination of Gemini 3 Flash pricing and performance. For businesses, the ability to deploy agentic workflows via Google Antigravity without breaking the bank is a competitive advantage that cannot be ignored.
Actionable Takeaway:
If you are still running your automated workflows on Gemini 2.5 or legacy GPT-4 models, you are likely overpaying for slower performance. Switch your API calls to Gemini 3 Flash today to reduce latency by 60% and cut costs by half.
Would you like me to generate a Python script to help you migrate your current API prompts to the new Gemini 3 Flash endpoint?


{kind=link}